
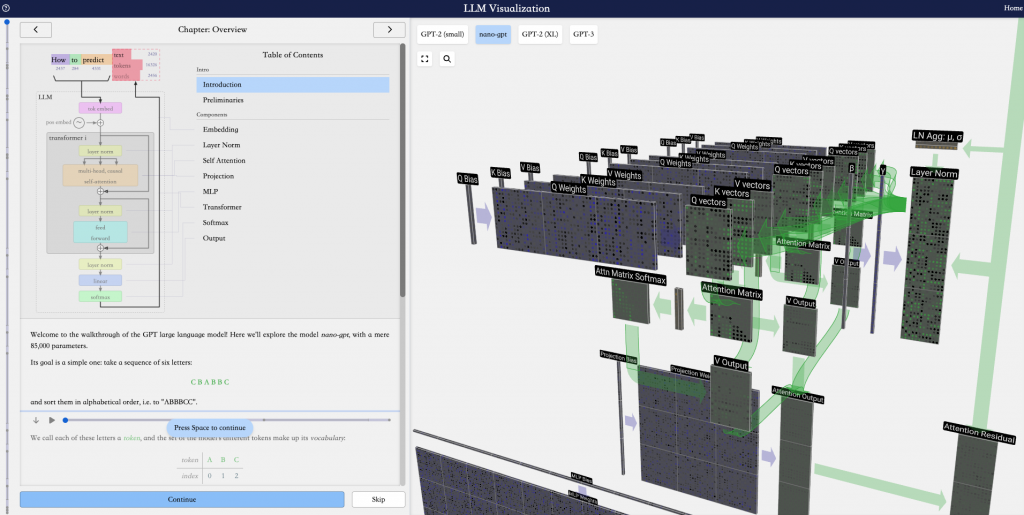
通过上图可知,nano-GPT是一种Transformer架构,Transformer是一种Encoder-Decoder架构,但GPT仅使用了Decoder部分,在Decoder中,每个Token对应的输出只能参考当前输入Token之前的Token,所以Decoder通常用于文本生成,也就是通过自回归方式预测下一个单词。
有只使用Decoder的,当然就有只使用Encoder的,Bert就是典型代表,在Encoder中,每个Token对应的输出是借鉴了所有的输入,所以Encoder更擅长文本理解。
还有一种则都用了,这是一种典型的seq2seq架构,Encoder用于捕获源seq的内在表示,Decoder则将捕获的表示解码成目标seq。典型的应用包括语言翻译,语音识别等等;
发表回复